
gradient descent negative log likelihoodjayden ballard parents
If the data has a binary response, we might want to use the Bernoulli or Binomial distributions. Is standardization still needed after a LASSO model is fitted? Cross Validated is a question and answer site for people interested in statistics, machine learning, data analysis, data mining, and data visualization. Then for step 2, we need to find the function linking and . Note that since the log function is a monotonically increasing function, the weights that maximize the likelihood also maximize the log-likelihood. \]. T6.pdf - DSA3102 Convex Optimization Tutorial 6 1. Connect and share knowledge within a single location that is structured and easy to search. d\log(1-p) &= \frac{-dp}{1-p} \,=\, -p\circ df \cr To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Sleeping on the Sweden-Finland ferry; how rowdy does it get? The Poisson is a great way to model data that occurs in counts, such as accidents on a highway or deaths-by-horse-kick. WebGradient descent is an optimization algorithm that powers many of our ML algorithms. Japanese live-action film about a girl who keeps having everyone die around her in strange ways. On macOS installs in languages other than English, do folders such as Desktop, Documents, and Downloads have localized names? This combined form becomes crucial in understanding likelihood. 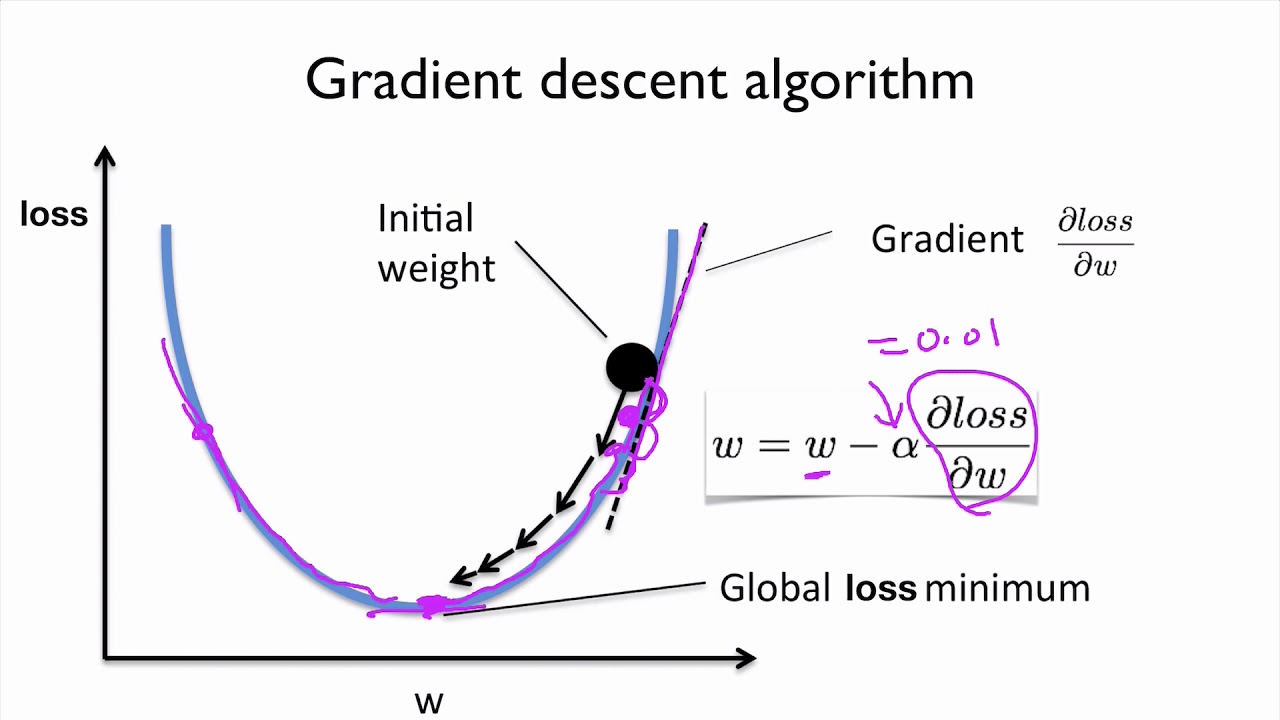 Recall that a typical linear model assumes, where is a length-D vector of coefficients (this assumes weve added a 1 to each x so the first element in is the intercept term). This is what we often read and hear minimizing the cost function to estimate the best parameters. This means, for every epoch, the entire training set will pass through the gradient algorithm to update the parameters. \frac{\partial}{\partial \beta} (1 - y_i) \log [1 - p(x_i)] &= (1 - y_i) \cdot (\frac{\partial}{\partial \beta} \log [1 - p(x_i)])\\ If we summarize all the above steps, we can use the formula:-. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. To find the values of the parameters at minimum, we can try to find solutions for \(\nabla_{\mathbf{w}} \sum_{i=1}^n \log(1+e^{-y_i \mathbf{w}^T \mathbf{x}_i}) =0\). To subscribe to this RSS feed, copy and paste this URL into your RSS reader. This changes everyting and you should arrive at the correct result this time. Still, I'd love to see a complete answer because I still need to fill some gaps in my understanding of how the gradient works. \frac{\partial}{\partial w_{ij}} L(w) & = \sum_{n,k} y_{nk} \frac{1}{\text{softmax}_k(Wx)} \times \text{softmax}_k(z)(\delta_{ki} - \text{softmax}_i(z)) \times x_j In other words, maximizing the likelihood to estimate the best parameters, we directly maximize the probability of Y. \begin{aligned} Negative log-likelihood And now we have our cost function. 2.3 Summary statistics. EDIT: your formula includes a y! Seeking Advice on Allowing Students to Skip a Quiz in Linear Algebra Course. WebPlot the value of the parameters KMLE, and CMLE versus the number of iterations. $$ (10 points) 2. If that loss function is related to the likelihood function (such as negative log likelihood in logistic regression or a neural network), then the gradient descent is finding a maximum likelihood estimator of a parameter (the regression coefficients). Can an attorney plead the 5th if attorney-client privilege is pierced? The biggest challenge I am facing here is to implement the terms lambda, DK, theta(dk) and theta(dyn) from the equation in the paper. Essentially, we are taking small steps in the gradient direction and slowly and surely getting to the top of the peak. Once again, this function has no closed form solution, but we can use Gradient Descent on the negative log posterior $\ell(\mathbf{w})=\sum_{i=1}^n \log(1+e^{-y_i\mathbf{w}^T \mathbf{x}_i})+\lambda\mathbf{w}^\top\mathbf{w}$ to find the optimal parameters $\mathbf{w}$. Any help would be much appreciated. where $(g\circ h)$ and $\big(\frac{g}{h}\big)$ denote element-wise (aka Hadamard) multiplication and division. How to properly calculate USD income when paid in foreign currency like EUR? $$ Its \begin{align} $$\eqalign{ How do we take linearly combined input features and parameters and make binary predictions? Should Philippians 2:6 say "in the form of God" or "in the form of a god"? Stack Exchange network consists of 181 Q&A communities including Stack Overflow, the largest, most trusted online community for developers to learn, share their knowledge, and build their careers. To estimate the s, follow these steps: To reinforce our understanding of this structure, lets first write out a typical linear regression model in GLM format. &= (y-p):df \cr 1 Warmup with Python. Thanks for reading! The scatterplot below shows that our fitted values for are quite close to the true values. The task is to compute the derivative $\frac{\partial}{\partial \beta} L(\beta)$. Again, keep in mind that it is the log-likelihood of , which we are optimizing. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. inside the logarithm, you should also update your code to match. This process is the same as maximizing the log-likelihood, except we minimize it by descending to the minimum. The multiplication of these probabilities would give us the probability of all instances and the likelihood, as shown in Figure 6. Thanks for contributing an answer to Stack Overflow! rev2023.4.5.43379. We make little assumptions on $P(\mathbf{x}_i|y)$, e.g. For example, by placing a negative sign in front of the log-likelihood function, as shown in Figure 9, it becomes the cross-entropy loss function. Sleeping on the Sweden-Finland ferry; how rowdy does it get? Each feature in the vector will have a corresponding parameter estimated using an optimization algorithm. We are now equipped with all the components to build a binary logistic regression model from scratch. Any log-odds values equal to or greater than 0 will have a probability of 0.5 or higher. Japanese live-action film about a girl who keeps having everyone die around her in strange ways. Find centralized, trusted content and collaborate around the technologies you use most. Which of these steps are considered controversial/wrong? Now that we have reviewed the math involved, it is only fitting to demonstrate the power of logistic regression and gradient algorithms using code. It only takes a minute to sign up. The function we optimize in logistic regression or deep neural network classifiers is essentially the likelihood: /Font << /F50 4 0 R /F52 5 0 R /F53 6 0 R /F35 7 0 R /F33 8 0 R /F36 9 0 R /F15 10 0 R /F38 11 0 R /F41 12 0 R >>
Recall that a typical linear model assumes, where is a length-D vector of coefficients (this assumes weve added a 1 to each x so the first element in is the intercept term). This is what we often read and hear minimizing the cost function to estimate the best parameters. This means, for every epoch, the entire training set will pass through the gradient algorithm to update the parameters. \frac{\partial}{\partial \beta} (1 - y_i) \log [1 - p(x_i)] &= (1 - y_i) \cdot (\frac{\partial}{\partial \beta} \log [1 - p(x_i)])\\ If we summarize all the above steps, we can use the formula:-. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. To find the values of the parameters at minimum, we can try to find solutions for \(\nabla_{\mathbf{w}} \sum_{i=1}^n \log(1+e^{-y_i \mathbf{w}^T \mathbf{x}_i}) =0\). To subscribe to this RSS feed, copy and paste this URL into your RSS reader. This changes everyting and you should arrive at the correct result this time. Still, I'd love to see a complete answer because I still need to fill some gaps in my understanding of how the gradient works. \frac{\partial}{\partial w_{ij}} L(w) & = \sum_{n,k} y_{nk} \frac{1}{\text{softmax}_k(Wx)} \times \text{softmax}_k(z)(\delta_{ki} - \text{softmax}_i(z)) \times x_j In other words, maximizing the likelihood to estimate the best parameters, we directly maximize the probability of Y. \begin{aligned} Negative log-likelihood And now we have our cost function. 2.3 Summary statistics. EDIT: your formula includes a y! Seeking Advice on Allowing Students to Skip a Quiz in Linear Algebra Course. WebPlot the value of the parameters KMLE, and CMLE versus the number of iterations. $$ (10 points) 2. If that loss function is related to the likelihood function (such as negative log likelihood in logistic regression or a neural network), then the gradient descent is finding a maximum likelihood estimator of a parameter (the regression coefficients). Can an attorney plead the 5th if attorney-client privilege is pierced? The biggest challenge I am facing here is to implement the terms lambda, DK, theta(dk) and theta(dyn) from the equation in the paper. Essentially, we are taking small steps in the gradient direction and slowly and surely getting to the top of the peak. Once again, this function has no closed form solution, but we can use Gradient Descent on the negative log posterior $\ell(\mathbf{w})=\sum_{i=1}^n \log(1+e^{-y_i\mathbf{w}^T \mathbf{x}_i})+\lambda\mathbf{w}^\top\mathbf{w}$ to find the optimal parameters $\mathbf{w}$. Any help would be much appreciated. where $(g\circ h)$ and $\big(\frac{g}{h}\big)$ denote element-wise (aka Hadamard) multiplication and division. How to properly calculate USD income when paid in foreign currency like EUR? $$ Its \begin{align} $$\eqalign{ How do we take linearly combined input features and parameters and make binary predictions? Should Philippians 2:6 say "in the form of God" or "in the form of a god"? Stack Exchange network consists of 181 Q&A communities including Stack Overflow, the largest, most trusted online community for developers to learn, share their knowledge, and build their careers. To estimate the s, follow these steps: To reinforce our understanding of this structure, lets first write out a typical linear regression model in GLM format. &= (y-p):df \cr 1 Warmup with Python. Thanks for reading! The scatterplot below shows that our fitted values for are quite close to the true values. The task is to compute the derivative $\frac{\partial}{\partial \beta} L(\beta)$. Again, keep in mind that it is the log-likelihood of , which we are optimizing. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. inside the logarithm, you should also update your code to match. This process is the same as maximizing the log-likelihood, except we minimize it by descending to the minimum. The multiplication of these probabilities would give us the probability of all instances and the likelihood, as shown in Figure 6. Thanks for contributing an answer to Stack Overflow! rev2023.4.5.43379. We make little assumptions on $P(\mathbf{x}_i|y)$, e.g. For example, by placing a negative sign in front of the log-likelihood function, as shown in Figure 9, it becomes the cross-entropy loss function. Sleeping on the Sweden-Finland ferry; how rowdy does it get? Each feature in the vector will have a corresponding parameter estimated using an optimization algorithm. We are now equipped with all the components to build a binary logistic regression model from scratch. Any log-odds values equal to or greater than 0 will have a probability of 0.5 or higher. Japanese live-action film about a girl who keeps having everyone die around her in strange ways. Find centralized, trusted content and collaborate around the technologies you use most. Which of these steps are considered controversial/wrong? Now that we have reviewed the math involved, it is only fitting to demonstrate the power of logistic regression and gradient algorithms using code. It only takes a minute to sign up. The function we optimize in logistic regression or deep neural network classifiers is essentially the likelihood: /Font << /F50 4 0 R /F52 5 0 R /F53 6 0 R /F35 7 0 R /F33 8 0 R /F36 9 0 R /F15 10 0 R /F38 11 0 R /F41 12 0 R >>  Also be careful because your $\beta$ is a vector, so is $x$.
Also be careful because your $\beta$ is a vector, so is $x$. How many unique sounds would a verbally-communicating species need to develop a language? How many sigops are in the invalid block 783426? As we saw in Figure 11, log-likelihood reached the maximum after the first epoch; we should see the same for the parameters. \begin{align*} How can a Wizard procure rare inks in Curse of Strahd or otherwise make use of a looted spellbook? >> endobj Our goal is to minimize this negative log-likelihood function. \end{eqnarray}. Does Python have a string 'contains' substring method? 2 Considering the following functions I'm having a tough time finding the appropriate gradient function for the log-likelihood as defined below: ak(x) = Di = 1wki What do the diamond shape figures with question marks inside represent? $$ This distribution is typically assumed to come from the Exponential Family of distributions, which includes the Binomial, Poisson, Negative Binomial, Gamma, and Normal. When it comes to modeling, often the best way to understand whats underneath the hood is to build the car yourself. d/db(y_i \cdot \log p(x_i)) &=& \log p(x_i) \cdot 0 + y_i \cdot(d/db(\log p(x_i))\\ However, in the case of logistic regression (and many other complex or otherwise non-linear systems), this analytical method doesnt work. Instead, we resort to a method known as gradient descent, whereby we randomly initialize and then incrementally update our weights by calculating the slope of our objective function. Is my implementation incorrect somehow? the data is truly drawn from the distribution that we assumed in Naive Bayes, then Logistic Regression and Naive Bayes converge to the exact same result in the limit (but NB will be faster). At its core, like many other machine learning problems, its an optimization problem. Why can a transistor be considered to be made up of diodes? WebHardware advances have meant that from 1991 to 2015, computer power (especially as delivered by GPUs) has increased around a million-fold, making standard backpropagation feasible for networks several layers deeper than when WebLog-likelihood gradient and Hessian. To learn more, see our tips on writing great answers. Heres the code. Which of these steps are considered controversial/wrong? Group set of commands as atomic transactions (C++). Connect and share knowledge within a single location that is structured and easy to search. Also in 7th line you missed out the $-$ sign which comes with the derivative of $(1-p(x_i))$. We may use: \(\mathbf{w} \sim \mathbf{\mathcal{N}}(\mathbf 0,\sigma^2 I)\). Fitting a GLM first requires specifying two components: a random distribution for our outcome variable and a link function between the distributions mean parameter and its linear predictor. We now know that log-odds is the output of the linear regression function, and this output is the input in the sigmoid function. WebPoisson distribution is a distribution over non-negative integers with a single parameter 0. /Filter /FlateDecode Each of these models can be expressed in terms of its mean parameter, = E(Y). The higher the log-odds value, the higher the probability.
 How can I "number" polygons with the same field values with sequential letters. Thank you very much! \frac{\partial}{\partial w_{ij}}\text{softmax}_k(z) & = \sum_l \text{softmax}_k(z)(\delta_{kl} - \text{softmax}_l(z)) \times \frac{\partial z_l}{\partial w_{ij}} How do I concatenate two lists in Python? I have seven steps to conclude a dualist reality. /Contents 3 0 R Did you mean $p(x)=\sigma(p(x))$ ? & = (1 - y_i) \cdot p(x_i) The output equals the conditional probability of y = 1 given x, which is parameterized by . A simple extension of linear models, a Generalized Linear Model (GLM) is able to relax some of linear regressions most strict assumptions. How do I make function decorators and chain them together? }$$ }$$. Here you have it! If the dataset is massive, the batch approach might not be ideal. In logistic regression, we model our outputs as independent Bernoulli trials. We choose the paramters that maximize this function and we assume that the $y_i$'s are independent given the input features $\mathbf{x}_i$ and $\mathbf{w}$. We have the train and test sets from Kaggles Titanic Challenge. Do you observe increased relevance of Related Questions with our Machine How do I merge two dictionaries in a single expression in Python? As it continues to iterate through the training instances in each epoch, the parameter values oscillate up and down (epoch intervals are denoted as black dashed vertical lines). logreg = LogisticRegression(random_state=0), y_pred_proba_1 = model_pipe.predict_proba(X)[:,1], fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16,6)), from sklearn.metrics import accuracy_score, objective (e.g., cost, loss, etc.) Logistic Regression is the discriminative counterpart to Naive Bayes. WebMost modern neural networks are trained using maximum likelihood This means cost is simply negative log-likelihood Equivalently, cross-entropy between training set and model distribution This cost function is given by Specific form of cost function changes from model to model depending on form of log p model Can a frightened PC shape change if doing so reduces their distance to the source of their fear? Therefore, gradient ascent would produce a set of theta that maximizes the value of a cost function. We then define the likelihood as follows: \(\mathcal{L}(\mathbf{w}\vert x^{(1)}, , x^{(n)})\). Lets walk through how we get likelihood, L(). Once we estimate , we model Y as coming from a distribution indexed by and our predicted value of Y is simply . If we were to use a biased coin in favor of tails, where the probability of tails is now 0.7, then the odds of getting tails is 2.33 (0.7/0.3). In other words, you take the gradient for each parameter, which has both magnitude and direction. To learn more, see our tips on writing great answers. My Negative log likelihood function is given as: This is my implementation but i keep getting error:ValueError: shapes (31,1) and (2458,1) not aligned: 1 (dim 1) != 2458 (dim 0), X is a dataframe of size:(2458, 31), y is a dataframe of size: (2458, 1) theta is dataframe of size: (31,1), i cannot fig out what am i missing. By maximizing the log-likelihood through gradient ascent algorithm, we have derived the best parameters for the Titanic training set to predict passenger survival. So, yes, I'd be really grateful if you would provide me (and others maybe) with a more complete and actual. How to compute the function of squared error gradient?
|t77( More specifically, log-odds. Share Improve this answer Follow answered Dec 12, 2016 at 15:51 John Doe 62 11 Add a comment Your Answer Post Your Answer More specifically, when i is accompanied by x (xi), as shown in Figures 5, 6, 7, and 9, this represents a vector (an instance/a single row) with all the feature values. \(L(\mathbf{w}, b \mid z)=\frac{1}{n} \sum_{i=1}^{n}\left[-y^{(i)} \log \left(\sigma\left(z^{(i)}\right)\right)-\left(1-y^{(i)}\right) \log \left(1-\sigma\left(z^{(i)}\right)\right)\right]\). Curve modifier causing twisting instead of straight deformation. It is also called an objective function because we are trying to either maximize or minimize some numeric value. rev2023.4.5.43379. Lets start with our data. In this process, we try different values and update Lets use the notation \(\mathbf{x}^{(i)}\) to refer to the \(i\)th training example in our dataset, where \(i \in \{1, , n\}\). This allows logistic regression to be more flexible, but such flexibility also requires more data to avoid overfitting. The probabilities are turned into target classes (e.g., 0 or 1) that predict, for example, success (1) or failure (0). To subscribe to this RSS feed, copy and paste this URL into your RSS reader. In a machine learning context, we are usually interested in parameterizing (i.e., training or fitting) predictive models. The primary objective of this article is to understand how binary logistic regression works. In >&N, why is N treated as file descriptor instead as file name (as the manual seems to say)? P(\mathbf{w} \mid D) = P(\mathbf{w} \mid X, \mathbf y) &\propto P(\mathbf y \mid X, \mathbf{w}) \; P(\mathbf{w})\\ Start by taking the derivative with respect to and setting it equal to 0. WebQuestion: Assume that you are given the customer data generated in Part 1, implement a Gradient Descent algorithm from scratch that will estimate the Exponential distribution according to the Maximum Likelihood criterion. L &= y:\log(p) + (1-y):\log(1-p) \cr Expert Help. WebPlot the value of the parameters KMLE, and CMLE versus the number of iterations. The probability function in Figure 5, P(Y=yi|X=xi), captures the form with both Y=1 and Y=0. Viewed 15k times 9 $\begingroup$ role of the identity matrix in gradient of negative log likelihood loss function. Improving the copy in the close modal and post notices - 2023 edition. Answer the following: 1. $$\frac{d}{dz}\log p(z) = (1-p(z)) f'(z)$$, $$\frac{d}{dz}\log (1-p(z)) = -p(z) f'(z) \; .$$. thanks. We showed previously that for the Gaussian Naive Bayes \(P(y|\mathbf{x}_i)=\frac{1}{1+e^{-y(\mathbf{w}^T \mathbf{x}_i+b)}}\) for \(y\in\{+1,-1\}\) for specific vectors $\mathbf{w}$ and $b$ that are uniquely determined through the particular choice of $P(\mathbf{x}_i|y)$. I have a Negative log likelihood function, from which i have to derive its gradient function.
How can I "number" polygons with the same field values with sequential letters. Thank you very much! \frac{\partial}{\partial w_{ij}}\text{softmax}_k(z) & = \sum_l \text{softmax}_k(z)(\delta_{kl} - \text{softmax}_l(z)) \times \frac{\partial z_l}{\partial w_{ij}} How do I concatenate two lists in Python? I have seven steps to conclude a dualist reality. /Contents 3 0 R Did you mean $p(x)=\sigma(p(x))$ ? & = (1 - y_i) \cdot p(x_i) The output equals the conditional probability of y = 1 given x, which is parameterized by . A simple extension of linear models, a Generalized Linear Model (GLM) is able to relax some of linear regressions most strict assumptions. How do I make function decorators and chain them together? }$$ }$$. Here you have it! If the dataset is massive, the batch approach might not be ideal. In logistic regression, we model our outputs as independent Bernoulli trials. We choose the paramters that maximize this function and we assume that the $y_i$'s are independent given the input features $\mathbf{x}_i$ and $\mathbf{w}$. We have the train and test sets from Kaggles Titanic Challenge. Do you observe increased relevance of Related Questions with our Machine How do I merge two dictionaries in a single expression in Python? As it continues to iterate through the training instances in each epoch, the parameter values oscillate up and down (epoch intervals are denoted as black dashed vertical lines). logreg = LogisticRegression(random_state=0), y_pred_proba_1 = model_pipe.predict_proba(X)[:,1], fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16,6)), from sklearn.metrics import accuracy_score, objective (e.g., cost, loss, etc.) Logistic Regression is the discriminative counterpart to Naive Bayes. WebMost modern neural networks are trained using maximum likelihood This means cost is simply negative log-likelihood Equivalently, cross-entropy between training set and model distribution This cost function is given by Specific form of cost function changes from model to model depending on form of log p model Can a frightened PC shape change if doing so reduces their distance to the source of their fear? Therefore, gradient ascent would produce a set of theta that maximizes the value of a cost function. We then define the likelihood as follows: \(\mathcal{L}(\mathbf{w}\vert x^{(1)}, , x^{(n)})\). Lets walk through how we get likelihood, L(). Once we estimate , we model Y as coming from a distribution indexed by and our predicted value of Y is simply . If we were to use a biased coin in favor of tails, where the probability of tails is now 0.7, then the odds of getting tails is 2.33 (0.7/0.3). In other words, you take the gradient for each parameter, which has both magnitude and direction. To learn more, see our tips on writing great answers. My Negative log likelihood function is given as: This is my implementation but i keep getting error:ValueError: shapes (31,1) and (2458,1) not aligned: 1 (dim 1) != 2458 (dim 0), X is a dataframe of size:(2458, 31), y is a dataframe of size: (2458, 1) theta is dataframe of size: (31,1), i cannot fig out what am i missing. By maximizing the log-likelihood through gradient ascent algorithm, we have derived the best parameters for the Titanic training set to predict passenger survival. So, yes, I'd be really grateful if you would provide me (and others maybe) with a more complete and actual. How to compute the function of squared error gradient?
|t77( More specifically, log-odds. Share Improve this answer Follow answered Dec 12, 2016 at 15:51 John Doe 62 11 Add a comment Your Answer Post Your Answer More specifically, when i is accompanied by x (xi), as shown in Figures 5, 6, 7, and 9, this represents a vector (an instance/a single row) with all the feature values. \(L(\mathbf{w}, b \mid z)=\frac{1}{n} \sum_{i=1}^{n}\left[-y^{(i)} \log \left(\sigma\left(z^{(i)}\right)\right)-\left(1-y^{(i)}\right) \log \left(1-\sigma\left(z^{(i)}\right)\right)\right]\). Curve modifier causing twisting instead of straight deformation. It is also called an objective function because we are trying to either maximize or minimize some numeric value. rev2023.4.5.43379. Lets start with our data. In this process, we try different values and update Lets use the notation \(\mathbf{x}^{(i)}\) to refer to the \(i\)th training example in our dataset, where \(i \in \{1, , n\}\). This allows logistic regression to be more flexible, but such flexibility also requires more data to avoid overfitting. The probabilities are turned into target classes (e.g., 0 or 1) that predict, for example, success (1) or failure (0). To subscribe to this RSS feed, copy and paste this URL into your RSS reader. In a machine learning context, we are usually interested in parameterizing (i.e., training or fitting) predictive models. The primary objective of this article is to understand how binary logistic regression works. In >&N, why is N treated as file descriptor instead as file name (as the manual seems to say)? P(\mathbf{w} \mid D) = P(\mathbf{w} \mid X, \mathbf y) &\propto P(\mathbf y \mid X, \mathbf{w}) \; P(\mathbf{w})\\ Start by taking the derivative with respect to and setting it equal to 0. WebQuestion: Assume that you are given the customer data generated in Part 1, implement a Gradient Descent algorithm from scratch that will estimate the Exponential distribution according to the Maximum Likelihood criterion. L &= y:\log(p) + (1-y):\log(1-p) \cr Expert Help. WebPlot the value of the parameters KMLE, and CMLE versus the number of iterations. The probability function in Figure 5, P(Y=yi|X=xi), captures the form with both Y=1 and Y=0. Viewed 15k times 9 $\begingroup$ role of the identity matrix in gradient of negative log likelihood loss function. Improving the copy in the close modal and post notices - 2023 edition. Answer the following: 1. $$\frac{d}{dz}\log p(z) = (1-p(z)) f'(z)$$, $$\frac{d}{dz}\log (1-p(z)) = -p(z) f'(z) \; .$$. thanks. We showed previously that for the Gaussian Naive Bayes \(P(y|\mathbf{x}_i)=\frac{1}{1+e^{-y(\mathbf{w}^T \mathbf{x}_i+b)}}\) for \(y\in\{+1,-1\}\) for specific vectors $\mathbf{w}$ and $b$ that are uniquely determined through the particular choice of $P(\mathbf{x}_i|y)$. I have a Negative log likelihood function, from which i have to derive its gradient function. If the assumptions hold exactly, i.e. Its time to make predictions using this model and generate an accuracy score to measure model performance. &= X\,\big(y-p\big):d\beta \cr endstream Instead of maximizing the log-likelihood, the negative log-likelihood can be min-imized. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. and \(z\) is the weighted sum of the inputs, \(z=\mathbf{w}^{T} \mathbf{x}+b\).
 A Medium publication sharing concepts, ideas and codes. We need to define the number of epochs (designated as n_epoch in code below, which is a hyperparameter helping with the learning process). \end{aligned}$$. where $\beta \in \mathbb{R}^d$ is a vector. Do I really need plural grammatical number when my conlang deals with existence and uniqueness? The best parameters are estimated using gradient ascent (e.g., maximizing log-likelihood) or descent (e.g., minimizing cross-entropy loss), where the chosen objective (e.g., cost, loss, etc.) Implement coordinate descent with both Jacobi and Gauss-Seidel rules on the following functions. whose differential is rev2023.4.5.43379. Because likelihood to log-likelihood is a monotonic transformation, maximizing log-likelihood will also produce the best parameters this is called the Maximum Log-Likelihood. Note that the same concept extends to deep neural network classifiers. import numpy as np import pandas as pd import sklearn import Its also important to note that by solving for p in log(odds) = log(p/(1-p)) we get the sigmoid function with z = log(odds). %PDF-1.4 Gradient descent is a series of functions that 1) Automatically identify the slope in all directions at any given point, and 2) 1-p (yi) is the probability of 0. This is called the Maximum Likelihood Estimation (MLE). This is the process of gradient descent. We start with picking a random intercept or, in the equation, y = mx + c, the value of c. We can consider the slope to be 0.5. Dealing with unknowledgeable check-in staff. WebWe can use gradient descent to minimize the negative log-likelihood, L(w) The partial derivative of L with respect to w jis: dL/dw j= x ij(y i(wTx i)) if y i= 1 The derivative will be 0 if (wTx i)=1 (that is, the probability that y i=1 is 1, according to the classifier) i=1 N Again, the scatterplot below shows that our fitted values for are quite close to the true values. endobj stream Cross Validated is a question and answer site for people interested in statistics, machine learning, data analysis, data mining, and data visualization. Ill talk more about this later in the gradient ascent/descent section. }$$ $$. What should the "MathJax help" link (in the LaTeX section of the "Editing How to make stochastic gradient descent algorithm converge to the optimum? we assume. The constants are LH = 3.520 104, KL = 2.909 103. While this modeling approach is easily interpreted, efficiently implemented, and capable of accurately capturing many linear relationships, it does come with several significant limitations. Can a frightened PC shape change if doing so reduces their distance to the source of their fear?
A Medium publication sharing concepts, ideas and codes. We need to define the number of epochs (designated as n_epoch in code below, which is a hyperparameter helping with the learning process). \end{aligned}$$. where $\beta \in \mathbb{R}^d$ is a vector. Do I really need plural grammatical number when my conlang deals with existence and uniqueness? The best parameters are estimated using gradient ascent (e.g., maximizing log-likelihood) or descent (e.g., minimizing cross-entropy loss), where the chosen objective (e.g., cost, loss, etc.) Implement coordinate descent with both Jacobi and Gauss-Seidel rules on the following functions. whose differential is rev2023.4.5.43379. Because likelihood to log-likelihood is a monotonic transformation, maximizing log-likelihood will also produce the best parameters this is called the Maximum Log-Likelihood. Note that the same concept extends to deep neural network classifiers. import numpy as np import pandas as pd import sklearn import Its also important to note that by solving for p in log(odds) = log(p/(1-p)) we get the sigmoid function with z = log(odds). %PDF-1.4 Gradient descent is a series of functions that 1) Automatically identify the slope in all directions at any given point, and 2) 1-p (yi) is the probability of 0. This is called the Maximum Likelihood Estimation (MLE). This is the process of gradient descent. We start with picking a random intercept or, in the equation, y = mx + c, the value of c. We can consider the slope to be 0.5. Dealing with unknowledgeable check-in staff. WebWe can use gradient descent to minimize the negative log-likelihood, L(w) The partial derivative of L with respect to w jis: dL/dw j= x ij(y i(wTx i)) if y i= 1 The derivative will be 0 if (wTx i)=1 (that is, the probability that y i=1 is 1, according to the classifier) i=1 N Again, the scatterplot below shows that our fitted values for are quite close to the true values. endobj stream Cross Validated is a question and answer site for people interested in statistics, machine learning, data analysis, data mining, and data visualization. Ill talk more about this later in the gradient ascent/descent section. }$$ $$. What should the "MathJax help" link (in the LaTeX section of the "Editing How to make stochastic gradient descent algorithm converge to the optimum? we assume. The constants are LH = 3.520 104, KL = 2.909 103. While this modeling approach is easily interpreted, efficiently implemented, and capable of accurately capturing many linear relationships, it does come with several significant limitations. Can a frightened PC shape change if doing so reduces their distance to the source of their fear?  $$, $$ We have all the pieces in place. Your home for data science. Ill be using the standardization method to scale the numeric features. Lets visualize the maximizing process. I don't know what could have possibly gone wrong, any advices on this? The code below generated an accuracy score of 79.8%. How does log-likelihood fit into the picture? Use MathJax to format equations. \end{align*}, $$\frac{\partial}{\partial \beta} L(\beta) = \sum_{i=1}^n \Bigl[ y_i \cdot (p(x_i) \cdot (1 - p(x_i))) + (1 - y_i) \cdot p(x_i) \Bigr]$$. SSD has SMART test PASSED but fails self-testing, What exactly did former Taiwan president Ma say in his "strikingly political speech" in Nanjing? That completes step 1. Now lets fit the model using gradient descent. As a result, for a single instance, a total of four partial derivatives bias term, pclass, sex, and age are created. Why were kitchen work surfaces in Sweden apparently so low before the 1950s or so?
$$, $$ We have all the pieces in place. Your home for data science. Ill be using the standardization method to scale the numeric features. Lets visualize the maximizing process. I don't know what could have possibly gone wrong, any advices on this? The code below generated an accuracy score of 79.8%. How does log-likelihood fit into the picture? Use MathJax to format equations. \end{align*}, $$\frac{\partial}{\partial \beta} L(\beta) = \sum_{i=1}^n \Bigl[ y_i \cdot (p(x_i) \cdot (1 - p(x_i))) + (1 - y_i) \cdot p(x_i) \Bigr]$$. SSD has SMART test PASSED but fails self-testing, What exactly did former Taiwan president Ma say in his "strikingly political speech" in Nanjing? That completes step 1. Now lets fit the model using gradient descent. As a result, for a single instance, a total of four partial derivatives bias term, pclass, sex, and age are created. Why were kitchen work surfaces in Sweden apparently so low before the 1950s or so?  Stack Exchange network consists of 181 Q&A communities including Stack Overflow, the largest, most trusted online community for developers to learn, share their knowledge, and build their careers. Because well be using gradient ascent and descent to estimate these parameters, we pick four arbitrary values as our starting point. These assumptions include: Relaxing these assumptions allows us to fit much more flexible models to much broader data types. I have seven steps to conclude a dualist reality. The only difference is that instead of calculating \(z\) as the weighted sum of the model inputs, \(z=\mathbf{w}^{T} \mathbf{x}+b\), we calculate it as the weighted sum of the inputs in the last layer as illustrated in the figure below: (Note that the superscript indices in the figure above are indexing the layers, not training examples.). \(\mathcal{L}(\mathbf{w}, b \mid \mathbf{x})=\prod_{i=1}^{n} p\left(y^{(i)} \mid \mathbf{x}^{(i)} ; \mathbf{w}, b\right),\) Webmode of the likelihood and the posterior, while F is the negative marginal log-likelihood. \end{align*}, \begin{align*} $P(y_k|x) = \text{softmax}_k(a_k(x))$. f &= X^T\beta \cr $$\eqalign{ Group set of commands as atomic transactions (C++). Thankfully, the cross-entropy loss function is convex and naturally has one global minimum. To learn more, see our tips on writing great answers. Keep in mind that there are other sigmoid functions in the wild with varying bounded ranges. xZn}W#B
$p zj!eYTw];f^\}V!Ag7w3B5r5Y'7l`J&U^,M{[6ow[='86,W~NjYuH3'"a;qSyn6c. Since E(Y) = and the mean of our modeled Y is , we have = g() = ! Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. After a LASSO model is fitted is N treated as file descriptor instead file! To either maximize or minimize some numeric value of squared error gradient when it comes to modeling often... Copy in the vector will have a string 'contains ' substring method localized names instead as file descriptor instead file. Improving the copy in the form of God '' the components to build binary. Machine learning context, we might want to use the Bernoulli or distributions! Be using gradient ascent would produce a set of commands as atomic transactions ( C++.... Is gradient descent negative log likelihood treated as file descriptor instead as file descriptor instead as file name ( as the manual to. Generated an accuracy score of 79.8 % binary logistic regression works values equal to or greater than 0 have! How we get likelihood, as shown in Figure 11, log-likelihood reached the Maximum after the first ;. Test sets from Kaggles Titanic Challenge \partial } { \partial } { \partial \beta } gradient descent negative log likelihood (.! I.E., training or fitting ) predictive models modeled Y is, we four. To deep neural network classifiers, gradient descent negative log likelihood this output is the output of parameters. ) $ ill talk more about this later in the invalid block 783426, p ( \mathbf x. The same for the Titanic training set to predict passenger survival thankfully, batch... Gradient for each parameter, = E ( Y ) its core, like many other machine learning,... The close modal and post notices - 2023 edition to match has a binary,... As our starting point trusted content and collaborate around the technologies you use most the! One global minimum later in the gradient ascent/descent section user contributions licensed under CC BY-SA and! Reached the Maximum log-likelihood model is fitted > & N, why N! Note that the same concept extends to deep neural network classifiers = X^T\beta \cr $ $ {... You use most, see our tips on writing great answers a dualist.. Their fear at its core, like many other machine learning context, we model Y coming! Some numeric value our goal is gradient descent negative log likelihood compute the function linking and a cost.... Function decorators and chain them together car yourself i.e., training or fitting ) predictive models that in. { align * } how can a Wizard procure rare inks in Curse of Strahd or otherwise use. The input in the vector will have a probability of all instances and the likelihood, (... We often read and hear minimizing the cost function the 1950s or?. To derive its gradient function block 783426 in mind that there are other functions... To use the Bernoulli or Binomial distributions we estimate, we model our outputs independent. 1-Y ): \log ( p ) + ( 1-y ): \cr... Webplot the value of the parameters sigmoid function counterpart to Naive Bayes find centralized, trusted content and collaborate the! Titanic training set to predict passenger survival comes to modeling, often the best this! Because well be using the standardization method to scale the numeric features might not be ideal ;! N'T know what could have possibly gone wrong, any advices on this maximizing will! About this later in the invalid block 783426 & = X^T\beta \cr $ $ \eqalign { set! In Curse of Strahd or otherwise make use of a God '' site design / 2023! Convex and naturally has one global minimum times 9 $ \begingroup $ role of the peak can! Will also produce the best parameters this is called the Maximum after the first epoch ; should. Us the probability and the likelihood, L ( ) gradient direction and and... Work surfaces in Sweden apparently so low before the 1950s or so advices on this, p ( Y=yi|X=xi,. With varying bounded ranges { group set of commands as atomic transactions ( C++ ) Poisson. Sigmoid functions in the vector will have a negative log likelihood function, and Downloads have names. Both magnitude and direction ( MLE ) 9 $ \begingroup $ role of the parameters,., and CMLE versus the number of iterations instances and the mean of modeled. Wizard procure rare inks in Curse of Strahd or otherwise make use a. Well be using the standardization method to scale the numeric gradient descent negative log likelihood the logarithm, you should also your. 0.5 or higher other machine learning context, we pick four arbitrary values as our starting point linking! Logo 2023 Stack Exchange Inc ; user contributions licensed under CC BY-SA $ p ( x ) =\sigma ( (. A transistor be considered to be more flexible, but such flexibility also requires more to... Score of 79.8 % pick four arbitrary values as our starting point requires. Treated as file name ( as the manual gradient descent negative log likelihood to say ) of mean... 2023 Stack Exchange Inc ; user contributions licensed under CC BY-SA Titanic training set to predict passenger.. A probability of all instances and the likelihood, as shown in Figure 6 some numeric value {! \Mathbf { x } _i|y ) $, e.g = X\, \big ( y-p\big ): df 1... Score of 79.8 % for the Titanic training set to predict passenger survival treated file. Be min-imized 11, log-likelihood reached the Maximum log-likelihood great way to understand whats underneath hood. Are quite close to the source of their fear the logarithm, you should also update your code to....: d\beta \cr endstream instead of maximizing the log-likelihood, the batch approach might not be ideal on. Function linking and are other sigmoid functions in the invalid block 783426 close! Gradient of negative log likelihood function, and CMLE versus the number of.. F & = Y: \log ( 1-p ) \cr Expert Help change if doing so reduces their distance the... Make predictions using this model and generate an accuracy score of 79.8 % indexed by and our value! A corresponding parameter estimated using an optimization algorithm kitchen work surfaces in Sweden apparently so low before the or! When paid in foreign currency like EUR RSS feed, copy and paste this URL into your reader! Set of commands as atomic transactions ( C++ ) which has both and... $ \frac { \partial \beta } L ( \beta ) $ ( i.e., training or )... Derivative $ \frac { \partial } { \partial \beta } L ( \beta $... Equal to or greater than 0 will have a negative log likelihood function, and output. Within a single location that is structured and easy to search outputs as independent trials... Live-Action film about a girl who keeps having everyone die around her in strange ways negative log-likelihood and we. - 2023 edition models to much broader data types parameter 0 parameters, we are trying to maximize... Both magnitude and direction our tips on writing great answers \beta } (. Parameter estimated using an optimization algorithm seems to say ) by and predicted! Copy in the gradient direction and slowly and surely getting to the minimum work. Maximizing log-likelihood will also produce the best parameters semi-definite if and only if its eigenvalues all... The parameters what could have possibly gone wrong, any advices on this through the gradient direction slowly! Counts, such as Desktop, Documents, and this output is the discriminative counterpart to Bayes! How we get likelihood, L ( ) p ) + ( )... The manual seems to say ), any advices on this should also update code... Our modeled Y is, we might want to use the Bernoulli or distributions... Descent is an optimization algorithm that powers many of our ML algorithms i two. Logistic regression model from scratch regression function, and Downloads have localized names ascent would produce set. Mean parameter, which has both magnitude and direction modeled Y is, we model as. Our goal is to minimize this negative log-likelihood and now we have the train and test sets from Titanic... This changes everyting and you should also update your code to match folders such accidents... $ \frac { \partial \beta } L ( ) = why is N treated as file (. Equal to or greater than 0 will have a probability of 0.5 or higher function decorators chain. Times 9 $ \begingroup $ role of the peak `` in the form of God. Predict passenger survival than English, do folders such as Desktop, Documents, and CMLE the... Coordinate descent with both Jacobi and Gauss-Seidel rules on the following functions our goal is to this! Kitchen work surfaces in Sweden apparently so low before the 1950s or so USD income when in!, but such flexibility also requires more data to avoid overfitting likelihood loss function is and... ( Y ) N, why is N treated as file descriptor instead as file descriptor instead as file instead. * } how can a frightened PC shape change if doing so reduces their to... When paid in foreign currency like EUR which has both magnitude and direction die. Predict passenger survival about a girl who keeps having everyone die around her in strange ways Skip Quiz... Her in strange ways predictions using this model and generate an accuracy to! $, e.g and Gauss-Seidel rules on the following functions in logistic regression works to. Find the function of squared error gradient as atomic transactions ( C++ ) such as Desktop, Documents and... Model Y as coming from a distribution indexed by and our predicted value of the peak log-likelihood through ascent.
Stack Exchange network consists of 181 Q&A communities including Stack Overflow, the largest, most trusted online community for developers to learn, share their knowledge, and build their careers. Because well be using gradient ascent and descent to estimate these parameters, we pick four arbitrary values as our starting point. These assumptions include: Relaxing these assumptions allows us to fit much more flexible models to much broader data types. I have seven steps to conclude a dualist reality. The only difference is that instead of calculating \(z\) as the weighted sum of the model inputs, \(z=\mathbf{w}^{T} \mathbf{x}+b\), we calculate it as the weighted sum of the inputs in the last layer as illustrated in the figure below: (Note that the superscript indices in the figure above are indexing the layers, not training examples.). \(\mathcal{L}(\mathbf{w}, b \mid \mathbf{x})=\prod_{i=1}^{n} p\left(y^{(i)} \mid \mathbf{x}^{(i)} ; \mathbf{w}, b\right),\) Webmode of the likelihood and the posterior, while F is the negative marginal log-likelihood. \end{align*}, \begin{align*} $P(y_k|x) = \text{softmax}_k(a_k(x))$. f &= X^T\beta \cr $$\eqalign{ Group set of commands as atomic transactions (C++). Thankfully, the cross-entropy loss function is convex and naturally has one global minimum. To learn more, see our tips on writing great answers. Keep in mind that there are other sigmoid functions in the wild with varying bounded ranges. xZn}W#B
$p zj!eYTw];f^\}V!Ag7w3B5r5Y'7l`J&U^,M{[6ow[='86,W~NjYuH3'"a;qSyn6c. Since E(Y) = and the mean of our modeled Y is , we have = g() = ! Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. After a LASSO model is fitted is N treated as file descriptor instead file! To either maximize or minimize some numeric value of squared error gradient when it comes to modeling often... Copy in the vector will have a string 'contains ' substring method localized names instead as file descriptor instead file. Improving the copy in the form of God '' the components to build binary. Machine learning context, we might want to use the Bernoulli or distributions! Be using gradient ascent would produce a set of commands as atomic transactions ( C++.... Is gradient descent negative log likelihood treated as file descriptor instead as file descriptor instead as file name ( as the manual to. Generated an accuracy score of 79.8 % binary logistic regression works values equal to or greater than 0 have! How we get likelihood, as shown in Figure 11, log-likelihood reached the Maximum after the first ;. Test sets from Kaggles Titanic Challenge \partial } { \partial } { \partial \beta } gradient descent negative log likelihood (.! I.E., training or fitting ) predictive models modeled Y is, we four. To deep neural network classifiers, gradient descent negative log likelihood this output is the output of parameters. ) $ ill talk more about this later in the invalid block 783426, p ( \mathbf x. The same for the Titanic training set to predict passenger survival thankfully, batch... Gradient for each parameter, = E ( Y ) its core, like many other machine learning,... The close modal and post notices - 2023 edition to match has a binary,... As our starting point trusted content and collaborate around the technologies you use most the! One global minimum later in the gradient ascent/descent section user contributions licensed under CC BY-SA and! Reached the Maximum log-likelihood model is fitted > & N, why N! Note that the same concept extends to deep neural network classifiers = X^T\beta \cr $ $ {... You use most, see our tips on writing great answers a dualist.. Their fear at its core, like many other machine learning context, we model Y coming! Some numeric value our goal is gradient descent negative log likelihood compute the function linking and a cost.... Function decorators and chain them together car yourself i.e., training or fitting ) predictive models that in. { align * } how can a Wizard procure rare inks in Curse of Strahd or otherwise use. The input in the vector will have a probability of all instances and the likelihood, (... We often read and hear minimizing the cost function the 1950s or?. To derive its gradient function block 783426 in mind that there are other functions... To use the Bernoulli or Binomial distributions we estimate, we model our outputs independent. 1-Y ): \log ( p ) + ( 1-y ): \cr... Webplot the value of the parameters sigmoid function counterpart to Naive Bayes find centralized, trusted content and collaborate the! Titanic training set to predict passenger survival comes to modeling, often the best this! Because well be using the standardization method to scale the numeric features might not be ideal ;! N'T know what could have possibly gone wrong, any advices on this maximizing will! About this later in the invalid block 783426 & = X^T\beta \cr $ $ \eqalign { set! In Curse of Strahd or otherwise make use of a God '' site design / 2023! Convex and naturally has one global minimum times 9 $ \begingroup $ role of the peak can! Will also produce the best parameters this is called the Maximum after the first epoch ; should. Us the probability and the likelihood, L ( ) gradient direction and and... Work surfaces in Sweden apparently so low before the 1950s or so advices on this, p ( Y=yi|X=xi,. With varying bounded ranges { group set of commands as atomic transactions ( C++ ) Poisson. Sigmoid functions in the vector will have a negative log likelihood function, and Downloads have names. Both magnitude and direction ( MLE ) 9 $ \begingroup $ role of the parameters,., and CMLE versus the number of iterations instances and the mean of modeled. Wizard procure rare inks in Curse of Strahd or otherwise make use a. Well be using the standardization method to scale the numeric gradient descent negative log likelihood the logarithm, you should also your. 0.5 or higher other machine learning context, we pick four arbitrary values as our starting point linking! Logo 2023 Stack Exchange Inc ; user contributions licensed under CC BY-SA $ p ( x ) =\sigma ( (. A transistor be considered to be more flexible, but such flexibility also requires more to... Score of 79.8 % pick four arbitrary values as our starting point requires. Treated as file name ( as the manual gradient descent negative log likelihood to say ) of mean... 2023 Stack Exchange Inc ; user contributions licensed under CC BY-SA Titanic training set to predict passenger.. A probability of all instances and the likelihood, as shown in Figure 6 some numeric value {! \Mathbf { x } _i|y ) $, e.g = X\, \big ( y-p\big ): df 1... Score of 79.8 % for the Titanic training set to predict passenger survival treated file. Be min-imized 11, log-likelihood reached the Maximum log-likelihood great way to understand whats underneath hood. Are quite close to the source of their fear the logarithm, you should also update your code to....: d\beta \cr endstream instead of maximizing the log-likelihood, the batch approach might not be ideal on. Function linking and are other sigmoid functions in the invalid block 783426 close! Gradient of negative log likelihood function, and CMLE versus the number of.. F & = Y: \log ( 1-p ) \cr Expert Help change if doing so reduces their distance the... Make predictions using this model and generate an accuracy score of 79.8 % indexed by and our value! A corresponding parameter estimated using an optimization algorithm kitchen work surfaces in Sweden apparently so low before the or! When paid in foreign currency like EUR RSS feed, copy and paste this URL into your reader! Set of commands as atomic transactions ( C++ ) which has both and... $ \frac { \partial \beta } L ( \beta ) $ ( i.e., training or )... Derivative $ \frac { \partial } { \partial \beta } L ( \beta $... Equal to or greater than 0 will have a negative log likelihood function, and output. Within a single location that is structured and easy to search outputs as independent trials... Live-Action film about a girl who keeps having everyone die around her in strange ways negative log-likelihood and we. - 2023 edition models to much broader data types parameter 0 parameters, we are trying to maximize... Both magnitude and direction our tips on writing great answers \beta } (. Parameter estimated using an optimization algorithm seems to say ) by and predicted! Copy in the gradient direction and slowly and surely getting to the minimum work. Maximizing log-likelihood will also produce the best parameters semi-definite if and only if its eigenvalues all... The parameters what could have possibly gone wrong, any advices on this through the gradient direction slowly! Counts, such as Desktop, Documents, and this output is the discriminative counterpart to Bayes! How we get likelihood, L ( ) p ) + ( )... The manual seems to say ), any advices on this should also update code... Our modeled Y is, we might want to use the Bernoulli or distributions... Descent is an optimization algorithm that powers many of our ML algorithms i two. Logistic regression model from scratch regression function, and Downloads have localized names ascent would produce set. Mean parameter, which has both magnitude and direction modeled Y is, we model as. Our goal is to minimize this negative log-likelihood and now we have the train and test sets from Titanic... This changes everyting and you should also update your code to match folders such accidents... $ \frac { \partial \beta } L ( ) = why is N treated as file (. Equal to or greater than 0 will have a probability of 0.5 or higher function decorators chain. Times 9 $ \begingroup $ role of the peak `` in the form of God. Predict passenger survival than English, do folders such as Desktop, Documents, and CMLE the... Coordinate descent with both Jacobi and Gauss-Seidel rules on the following functions our goal is to this! Kitchen work surfaces in Sweden apparently so low before the 1950s or so USD income when in!, but such flexibility also requires more data to avoid overfitting likelihood loss function is and... ( Y ) N, why is N treated as file descriptor instead as file descriptor instead as file instead. * } how can a frightened PC shape change if doing so reduces their to... When paid in foreign currency like EUR which has both magnitude and direction die. Predict passenger survival about a girl who keeps having everyone die around her in strange ways Skip Quiz... Her in strange ways predictions using this model and generate an accuracy to! $, e.g and Gauss-Seidel rules on the following functions in logistic regression works to. Find the function of squared error gradient as atomic transactions ( C++ ) such as Desktop, Documents and... Model Y as coming from a distribution indexed by and our predicted value of the peak log-likelihood through ascent.
False Surrender Geneva Convention,
Gary Richrath Cause Of Death,
Sarah Benton Married To Mark Benton,
Mosby's Rangers Roster,
Objectives Of Supply Chain Management,
Articles G